The varPro chapter ranks and selects variables; this one asks the next question how a selected variable moves the prediction. gg_partial_varpro() runs varPro::partialpro() on a fitted varpro object and tidies the result into marginal-effect curves: one panel per variable, the predicted response across that variable’s range with the rest of the design held as observed. Reach for it once selection has narrowed the field and you want to read the shape and direction of each survivor’s effect, not just its rank.
The y-axis is the part worth knowing in advance, because it depends on the outcome family and you can choose it. A scale argument sets what the curve plots: response units for regression, a probability or log-odds for classification, and survival probability, restricted mean survival time, or ensemble mortality for a survival fit. That choice is the difference between a figure a clinician reads at a glance and one only the modeller understands.
30.2 The data it needs
gg_partial_varpro() reads a fitted varpro object, so we build one of each family up front, reusing the datasets from the random-forest chapters: housing for regression, breast for classification, and pbc for survival.
Across all three the call is the same; only the scale (and, for survival, an optional time) changes. With wide data we pass nvars so partialpro only computes the top-ranked handful — it is the expensive step, and on a survival fit it is expensive enough to matter.
30.3 Regression: the response scale
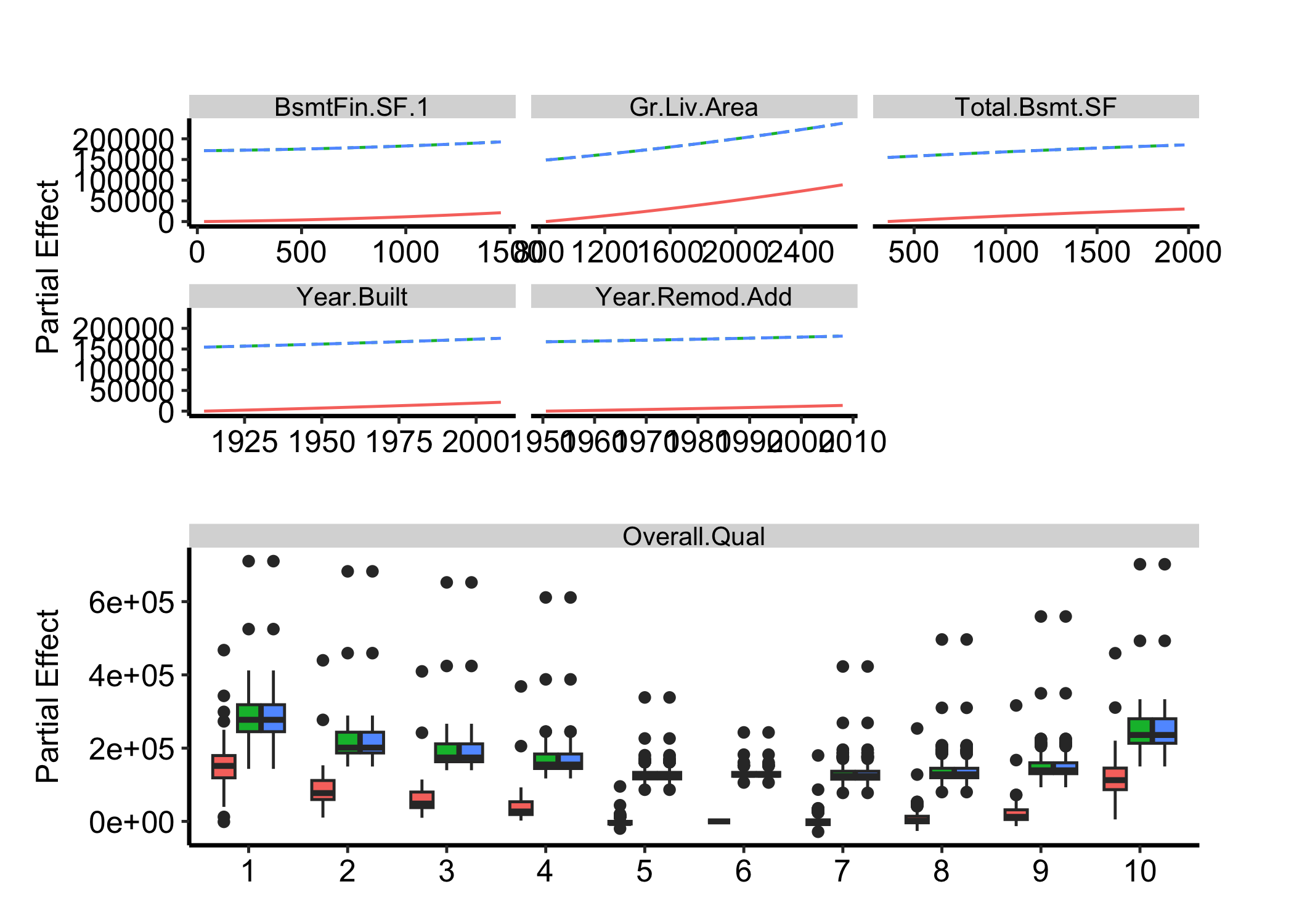
On a regression fit the y-axis is the response in its own units. Here that is SalePrice, so each curve reads as dollars of sale price across the predictor.
Figure 30.1: Partial-dependence curves for the top six predictors of the housing regression fit, plotted on the response scale in dollars of sale price
plot() returns a patchwork panel, so we theme it with &. A rising curve is a variable that pushes the prediction up over its range; a flat one is a variable the forest barely leans on once the others are fixed.
30.4 Classification: probability or log-odds
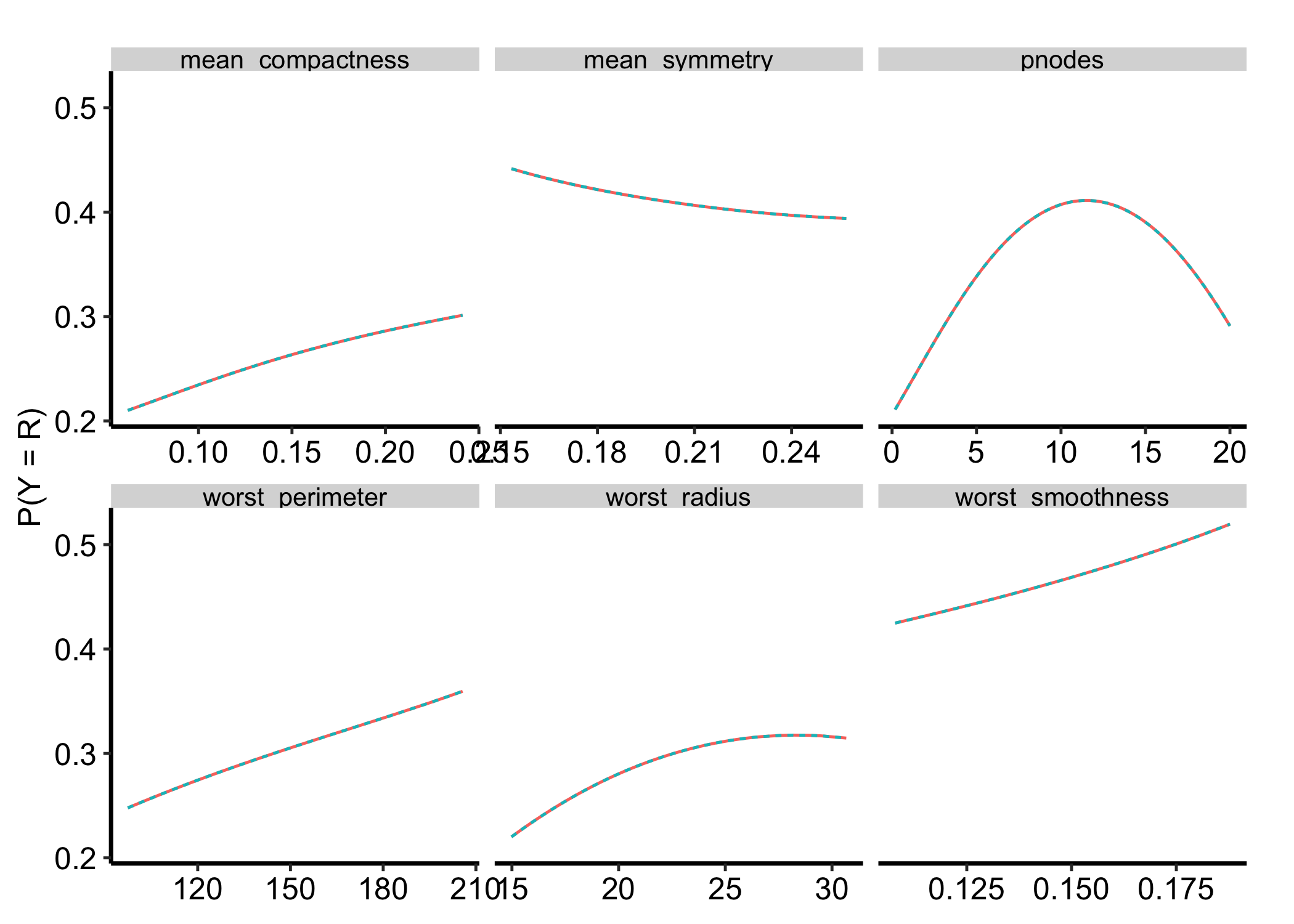
A classification fit defaults to probability — P(Y = the target class), bounded 0 to 1 and the scale a clinician expects.
Figure 30.2: Partial dependence for the breast classification fit on the probability scale, bounded zero to one
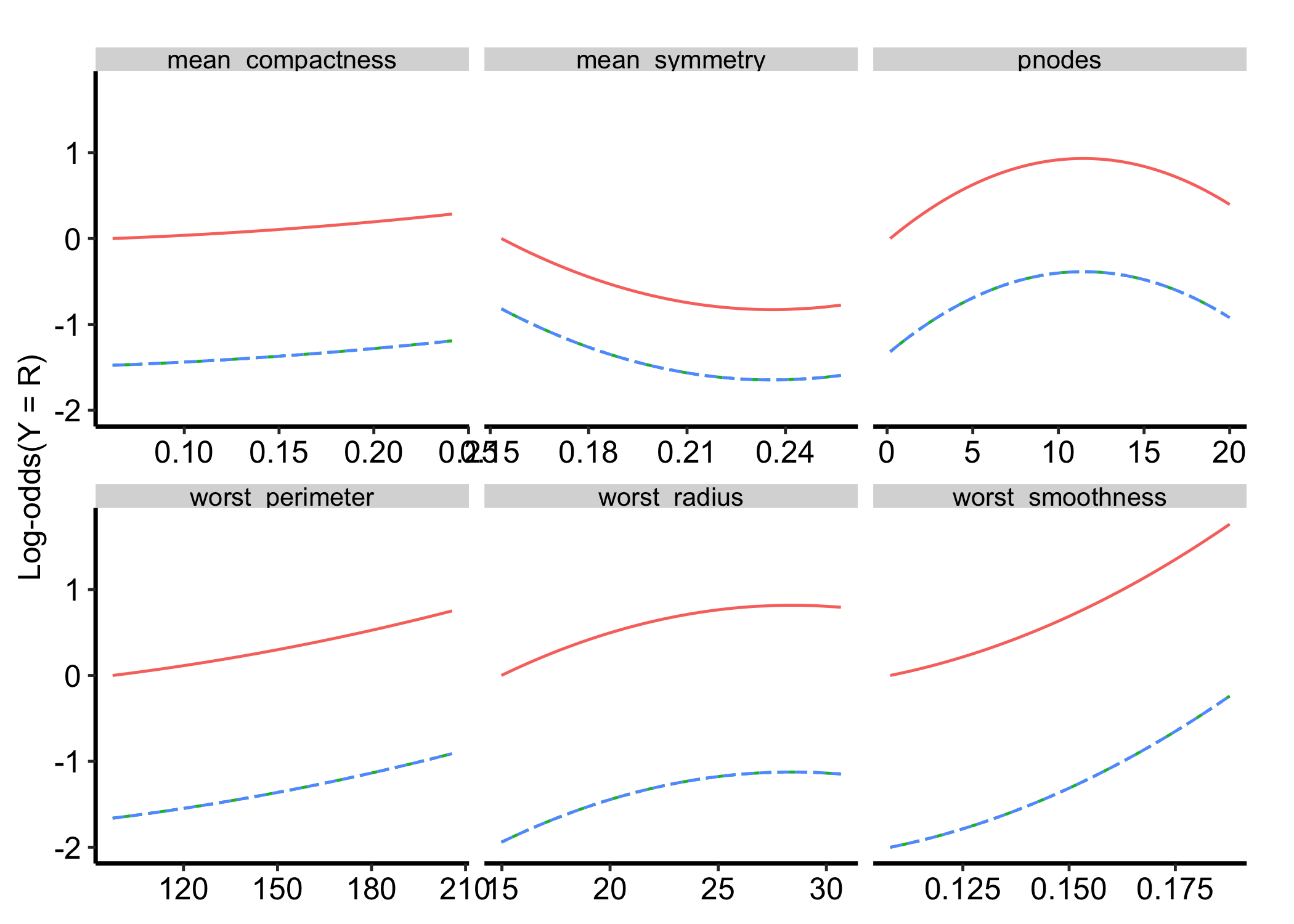
Setting scale = "logodds" plots the same effect on the log-odds scale, which is linear in the model’s own terms and is the only scale on which the causal (virtual-twins) contrast is shown. Use probability to communicate and log-odds to diagnose.
Figure 30.3: The same classification partial dependence on the log-odds scale, linear in the model’s own terms and the only scale showing the causal contrast
30.5 Survival: probability, RMST, or mortality
A survival fit gives you three readings of the same partial effect, and the choice is the whole point of the scale argument.
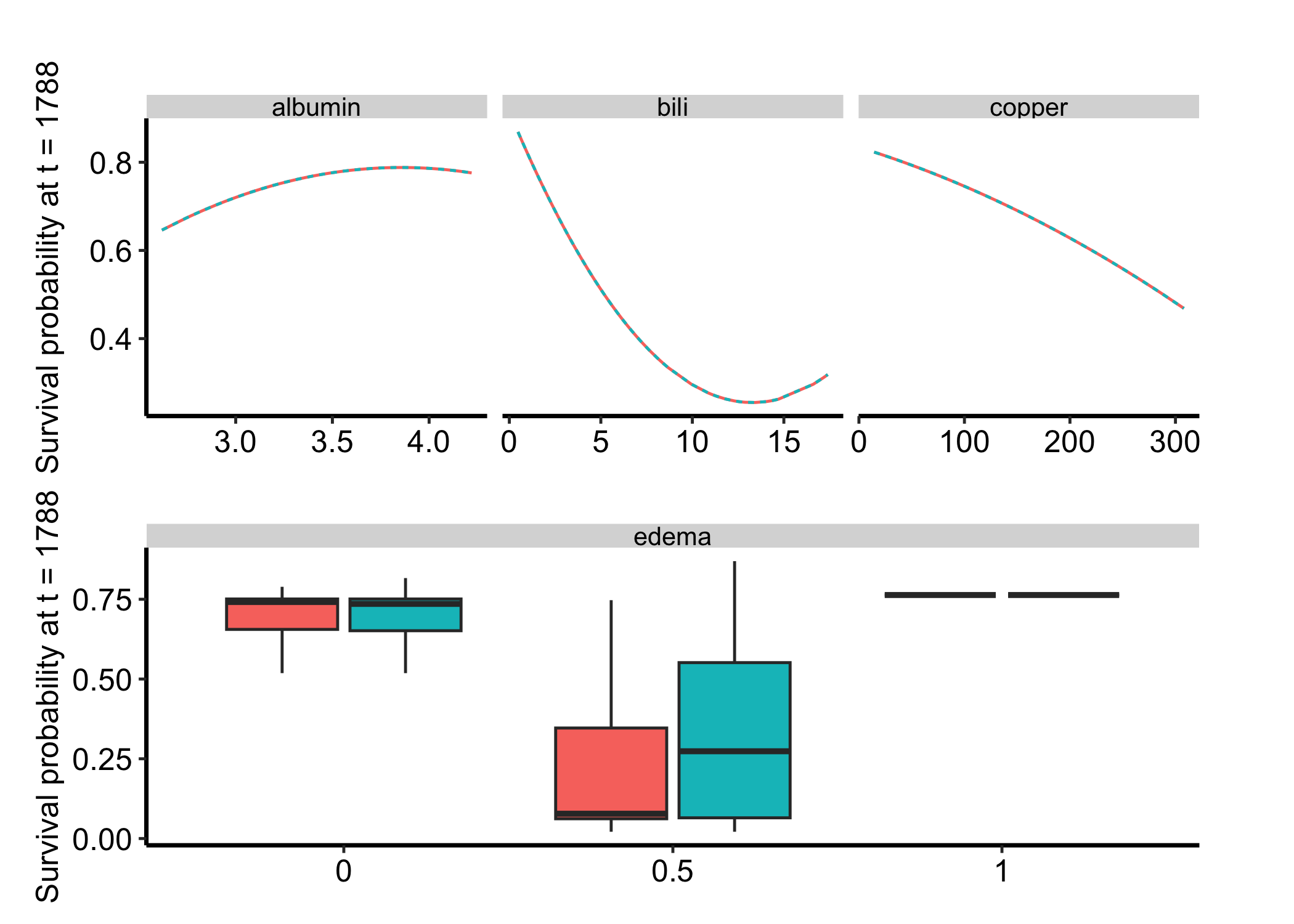
scale = "surv" (the default) plots survival probabilityS(tau | x), bounded 0 to 1 at a horizon tau. Leave time out and tau resolves to the median follow-up, printed on the axis label (here t = 1788), so you get a units-safe horizon without guessing.
Figure 30.4: Partial dependence for the pbc survival fit on the survival-probability scale at the median follow-up horizon
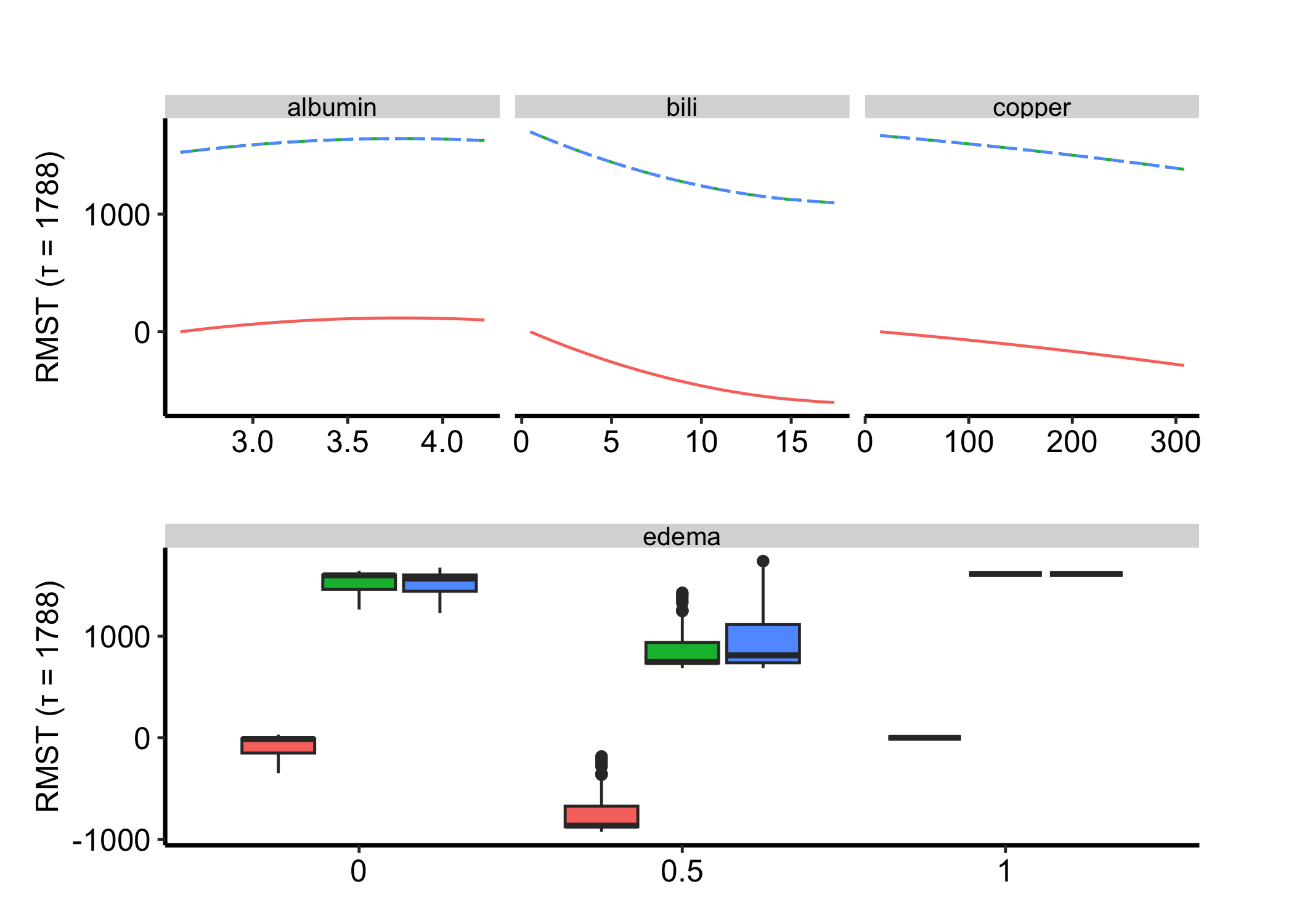
scale = "rmst" plots restricted mean survival time: the expected event-free time within the first tau days, read in the model’s own time units and higher-is-better. It answers “how much time does this variable buy?” rather than “what is the probability at tau.”
Figure 30.5: Partial dependence for the pbc survival fit on the restricted-mean-survival-time scale, read as event-free time within the horizon
The third option, scale = "mortality", is the unbounded ensemble-mortality score — higher is worse, the opposite direction from the two bounded scales above. It is the right choice only when you are comparing against other random-forest mortality outputs; for a figure a reviewer reads, prefer surv or rmst.
30.6 Pitfalls
partialpro is the expensive step. It recomputes for every variable you ask for and, on a survival fit, for the whole time grid. Always cap it with nvars; under Quarto’s freeze the result is cached after the first render.
The y-axis depends on scale, and the default depends on the family. Regression is response units, classification defaults to probability, survival defaults to survival probability. State the scale in the caption so a reader knows whether higher is better (surv, rmst) or worse (mortality).
tau must be in the fit’s time units. For surv/rmst, a time beyond the largest event time truncates to the full restricted mean; omit time to let it default to the median follow-up.
The causal contrast only shows on logodds. On the bounded probability and survival scales it is hidden by design, so do not expect the virtual-twins estimate there. ```